Loading Instructions for BSBM
Postgres Loading
Creation of Dumps
Download generator:
mkdir -p dump cd dump wget "https://downloads.sourceforge.net/project/bsbmtools/bsbmtools/bsbmtools-0.2/bsbmtools-v0.2.zip?r=https%3A%2F%2Fsourceforge.net%2Fprojects%2Fbsbmtools%2Ffiles%2Flatest%2Fdownload&ts=1552465981" -O bsbmtools-v0.2.zip unzip bsbmtools-v0.2.zip cd bsbmtools-0.2 ant
Generate one million triples nt file (not necessary)
cd dump/bsbmtools-0.2/ # use -s sql for SQL dump ./generate -pc 2810 -fn bsbm1m -nof 1 #./generate -pc 30000 -fn bsbm10m -nof 1 #./generate -pc 45000 -fn bsbm15m -nof 1 #./generate -pc 60000 -fn bsbm20m -nof 1 #./generate -pc 150000 -fn bsbm50m -nof 1 #./generate -pc 300000 -fn bsbm100m -nof 1 mv bsbm*m.nt ../
Create a MySQL dump of 1M triples:
cd bsbmtools-0.2/
./generate -pc 2810 -fn bsbm1m -nof 1 -s sql
mv bsbm*m ../
Load SQL Dump into Postgres
1M triples
The dump contains one file per table:
ls dump/bsbm1m/
Set the database name to bsbm1msql1:
sed -i 's/`benchmark`/`bsbm1msql`/g' bsbm1m/*.sql
First, we need to translate MySQL dump to PostgreSQL compatible dump
cd dump/bsbm1m # replacements sed -i 's/CREATE DATABASE IF NOT EXISTS/CREATE DATABASE/g' *.sql sed -i 's/ DEFAULT CHARACTER SET utf8//g' *.sql sed -i 's/`//g' *.sql sed -i 's/USE/\\c/g' *.sql sed -i 's/int\s*([[:digit:]]\+)/integer/g' *.sql sed -i 's/price double default/price double precision default/g' *.sql sed -i 's/ datetime/ date/g' *.sql #sed -i 's/INDEX USING BTREE/PRIMARY KEY/g' *.sql sed -i 's/ENGINE=InnoDB DEFAULT CHARSET=utf8//g' *.sql sed -i 's/character set utf8 collate utf8_bin//g' *.sql # deletion of line sed -i '/ALTER TABLE/d' *.sql sed -i '/LOCK TABLES/d' *.sql sed -i '/UNLOCK TABLES/d' *.sql
Remove manually lines starting by INDEX USING BTREE (row) in table creation instruction and add the following instruction:
CREATE INDEX ON table (row);
Then we execute the dump in postgres:
cd dump/bsbm1m
psql -f 01ProductFeature.sql
psql -f 02ProductType.sql
psql -f 03Producer.sql
psql -f 04Product.sql
psql -f 05ProductTypeProduct.sql
psql -f 06ProductFeatureProduct.sql
psql -f 07Vendor.sql
psql -f 08Offer.sql
psql -f 09Person.sql
psql -f 10Review.sql
We look at the loaded tables:
\dt
| List of relations | |||
|---|---|---|---|
| Schema | Name | Type | Owner |
| public | countrytype | table | postgres |
| public | offer | table | postgres |
| public | person | table | postgres |
| public | producer | table | postgres |
| public | product | table | postgres |
| public | productfeature | table | postgres |
| public | productfeatureproduct | table | postgres |
| public | producttype | table | postgres |
| public | producttypeproduct | table | postgres |
| public | review | table | postgres |
| public | vendor | table | postgres |
SELECT DISTINCT nr,producer,label from product LIMIT 10;
| nr | producer | label |
|---|---|---|
| 1656 | 37 | sennits levelling |
| 162 | 4 | plotties dogs |
| 11 | 1 | pipers pests |
| 2111 | 45 | droopily presoak dieresis |
| 297 | 7 | whimpered candors arbitrator |
| 200 | 5 | thrivers |
| 736 | 16 | immunizing incommodious woolly |
| 2606 | 55 | anaesthetized rides untainted |
| 700 | 15 | reattempting |
| 479 | 10 | etiologic lawmaker rassles |
SELECT DISTINCT nr,title,product,person,rating1 from review LIMIT 10;
| nr | title | product | person | rating1 |
|---|---|---|---|---|
| 1 | ordainers peacoats grindstones syphon translators xerophthalmia colonise abbotcy tenements gasps banked sandiness furrower | 1039 | 1 | |
| 2 | icecap soapmaking pugilistic clept decried innuendos tonsured | 1103 | 1 | 5 |
| 3 | smidgens skinhead reservists flytrap shorteners freelanced defalcating chloroformed accruement ionization jurors populates wireless gradients | 823 | 1 | 3 |
| 4 | acknowledgers dilapidated ruddier disloyalties legislatrices scribal backstops appellor unreeling symptomatologies blandisher peacefully corvets worthier unwearable | 2172 | 1 | |
| 5 | proportional sneezy qualifiers tinseled thalamus gearshifts unincorporated watering expanders innocents | 2162 | 1 | 9 |
| 6 | remarries trilobed tongers waved squads disenchanted | 1332 | 1 | 3 |
| 7 | vegetarianism knits nanoseconds tassels jouncing optimization heftier bestially intrigues aftercare cheapened collapsing loungy hydrometers | 2671 | 1 | 3 |
| 8 | strawhat gels redemanding mappers ribgrasses enflames pocketer tzarevnas boondoggles housefuls insurgences muggering simplexes horary nanowatt | 797 | 1 | 4 |
| 9 | militarized erector strapping hazers repliers injection scepters sparked taunting rehydrating cariocas wallpapered oilcans madrones druidesses | 1387 | 1 | 7 |
| 10 | uniters prenames wen griddles genially fastens defamers skylarker circuits akimbo | 1455 | 1 | 9 |
SELECT count(*) from productfeature;
| count |
|---|
| 4745 |
50M triples
Download the prepared dump for Postgres. And uncompress it:
tar xf bsbm50m.tar.xz
Then load it into postgres:
cd dump/bsbm50m
psql -f 01ProductFeature.sql
psql -f 02ProductType.sql
psql -f 03Producer.sql
psql -f 04Product.sql
psql -f 05ProductTypeProduct.sql
psql -f 06ProductFeatureProduct.sql
psql -f 07Vendor.sql
psql -f 08Offer.sql
psql -f 09Person.sql
psql -f 10Review.sql
Core Ontology for BSBM
We create an ontology for BSBM benchmark according to the RDF schema. Some part of this ontology are imported from foaf ontology. You can download the ontology NT file, which contains 26 classes and 36 properties used in 40 subclass, 32 subproperty, 42 domain and 16 range definitions. This ontology contains a small hierarchy for the countries containing 14 sub-classes.

Figure 1: The BSBM core ontology
Country Type Hierarchy
We specify the type of each country using an SQL script putting randomly two countries in each leaves of the country types hierarchy.
Product Type Hierarchy
1 million triples
We produce the product type hierarchy for 1M triples using the following script:
export PGPASSWORD=postgres export PGUSER=postgres DB=bsbm1msql OUT=product-type-hierarchy/product-type-hierarchy1m.nt rm $OUT; eval $(psql -t -d $DB --field-separator ' ' --no-align -c "select distinct nr, parent from producttype ORDER BY nr ASC" | while read nr parent do if [ $parent != "" ] then echo "<http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/instances/ProductType$nr> <http://www.w3.org/2000/01/rdf-schema#subClassOf> <http://www4.wiwiss.fu-berlin.de/bizer/bsbm/v01/instances/ProductType$parent> ." >> $OUT fi done)
The ontology contains 150 subclass definitions:
wc -l product-type-hierarchy/product-type-hierarchy1m.nt
150 product-type-hierarchy/product-type-hierarchy1m.nt
The subclass hierarchy of products have balanced tree-shape of depth 3 and 151 classes, among them 96 are used in data.
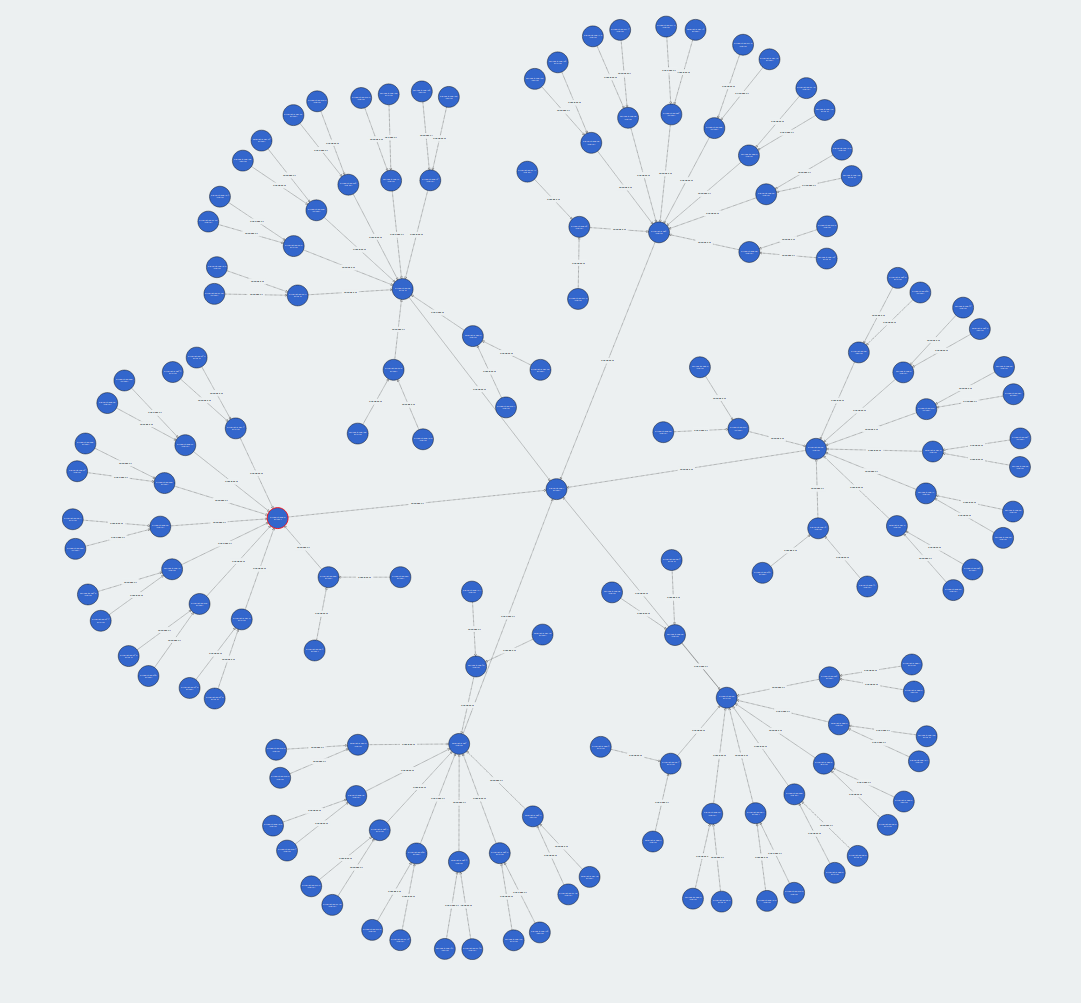
50 million triples
Reusing the above script, we create the product type hierarchy for 50M triples.
The ontology contains 2010 subclass definitions:
wc -l product-type-hierarchy/product-type-hierarchy50m.nt
2010 product-type-hierarchy/product-type-hierarchy50m.nt
The ontology have a balanced tree shape of 2011 classes of depth 4, 1280 classes are used in data:

MongoDB Loading
View Materialization in MongoDB for BSBM 1M
The chosen views contain 116 756 tuples (33,6% of the extensions tuples)
Offer table
select row_to_json(t) from ( SELECT nr, product, producer, vendor, price, validFrom, validTo, deliveryDays, offerWebpage, publisher, publishDate FROM Offer ) t
Vendor table translation
select row_to_json(t) from ( select nr, label, comment, homepage, publisher, publishDate FROM Vendor ) t
Country Types
select row_to_json(t) from ( SELECT * FROM CountryType ) t
View linking product feature properties to product with existential product feature
select row_to_json(t) from ( SELECT P.nr AS nr, P.producer AS producer, PF.label AS label, PF.comment AS comment, PF.publisher AS publisher, PF.publishDate AS publishDate FROM Product AS P, ProductFeatureProduct AS PFP, ProductFeature AS PF WHERE P.nr = PFP.product AND PFP.productFeature = PF.nr ) t
json/1m/productfeatureproduct.json
Producer country of product
select row_to_json(t) from ( SELECT P.nr AS nr, P.producer AS producer, PR.country AS country FROM Product AS P, Producer AS PR WHERE P.producer = PR.nr ) t
json/1m/productproducercountry.json
We load each of collections of JSON document into mongoDB:
mongoimport --drop -d bsbm1m -c offer --file json/1m/offer.json mongoimport --drop -d bsbm1m -c vendor --file json/1m/vendor.json mongoimport --drop -d bsbm1m -c countrytype --file json/countrytype.json mongoimport --drop -d bsbm1m -c productfeatureproduct --file json/1m/productfeatureproduct.json mongoimport --drop -d bsbm1m -c productproducercountry --file json/1m/productproducercountry.json
We create the same indexes as for postgres:
use bsbm1m
db.offer.createIndex({nr:1})
db.offer.createIndex({product:1})
db.offer.createIndex({vendor:1})
db.vendor.createIndex({nr: 1})
db.productfeatureproduct.createIndex({nr: 1})
db.productfeatureproduct.createIndex({producer: 1})
db.productfeatureproduct.createIndex({nr: 1})
db.productproducercountry.createIndex({nr: 1})
db.productproducercountry.createIndex({producer: 1})
View Materialization in MongoDB for BSBM 50M
The chosen views contain 6 063 952 tuples (33,0% of the extensions tuples)
Offer table
select row_to_json(t) from ( SELECT nr, product, producer, vendor, price, validFrom, validTo, deliveryDays, offerWebpage, publisher, publishDate FROM Offer ) t
Vendor table translation
select row_to_json(t) from ( select nr, label, comment, homepage, publisher, publishDate FROM Vendor ) t
Country Types
select row_to_json(t) from ( SELECT * FROM CountryType ) t
View linking product feature properties to product with existential product feature
select row_to_json(t) from ( SELECT P.nr AS nr, P.producer AS producer, PF.label AS label, PF.comment AS comment, PF.publisher AS publisher, PF.publishDate AS publishDate FROM Product AS P, ProductFeatureProduct AS PFP, ProductFeature AS PF WHERE P.nr = PFP.product AND PFP.productFeature = PF.nr ) t
json/50m/productfeatureproduct.json
Producer country of product
select row_to_json(t) from ( SELECT P.nr AS nr, P.producer AS producer, PR.country AS country FROM Product AS P, Producer AS PR WHERE P.producer = PR.nr ) t
json/50m/productproducercountry.json
We load each of collections of JSON document into mongoDB:
mongoimport --drop -d bsbm50m -c offer --file json/50m/offer.json mongoimport --drop -d bsbm50m -c vendor --file json/50m/vendor.json mongoimport --drop -d bsbm50m -c countrytype --file json/countrytype.json mongoimport --drop -d bsbm50m -c productfeatureproduct --file json/50m/productfeatureproduct.json mongoimport --drop -d bsbm50m -c productproducercountry --file json/50m/productproducercountry.json
We create the same indexes as for postgres:
use bsbm50m
db.offer.createIndex({nr:1})
db.offer.createIndex({product:1})
db.offer.createIndex({vendor:1})
db.vendor.createIndex({nr: 1})
db.productfeatureproduct.createIndex({nr: 1})
db.productfeatureproduct.createIndex({producer: 1})
db.productfeatureproduct.createIndex({nr: 1})
db.productproducercountry.createIndex({nr: 1})
db.productproducercountry.createIndex({producer: 1})
GLAV Mappings Generation
Country Type Mappings
DB=bsbm1msql TMP=ris-bsbm-copy-existential-1m/country-type-mappings.json TEMPLATE=ris-bsbm-copy-existential-1m/country-type-template.json echo "" > $TMP eval $(psql -t -d $DB -c "select distinct countryType from CountryType ORDER BY countryType ASC" | while read VAR do if [ $VAR != "" ] then PATTERN=`printf 's/$type/%s/g' $VAR` MAP_DEF=`sed $PATTERN $TEMPLATE` echo $MAP_DEF >> $TMP fi done)
Typed GLAV Mapping for 1M triples
DB=bsbm1msql TMP=ris-bsbm-copy-existential-1m/product-prop-mappings.json OUT=ris-bsbm-copy-existential-1m/ris-bsbm-glav.json CORE=ris-bsbm-copy-existential-1m/ris-bsbm-glav-core.json TEMPLATE1=ris-bsbm-copy-existential-1m/offer-product-prop-template.json TEMPLATE2=ris-bsbm-copy-existential-1m/review-product-prop-template.json echo "" > $TMP eval $(psql -t -d $DB -c "select distinct producttype from producttypeproduct ORDER BY producttype ASC" | while read VAR do if [ $VAR != "" ] then PATTERN=`printf 's/$type/%s/g' $VAR` MAP_DEF1=`sed $PATTERN $TEMPLATE1` MAP_DEF2=`sed $PATTERN $TEMPLATE2` echo $MAP_DEF1 >> $TMP echo $MAP_DEF2 >> $TMP fi done)
Typed GLAV Mappings for 50M triples
DB=bsbm50msql TMP=ris-bsbm-copy-existential-50m/product-prop-mappings.json TEMPLATE1=ris-bsbm-copy-existential-1m/offer-product-prop-template.json TEMPLATE2=ris-bsbm-copy-existential-1m/review-product-prop-template.json echo "" > $TMP eval $(psql -t -d $DB -c "select distinct producttype from producttypeproduct ORDER BY producttype ASC" | while read VAR do if [ $VAR != "" ] then PATTERN=`printf 's/$type/%s/g' $VAR` MAP_DEF1=`sed $PATTERN $TEMPLATE1` MAP_DEF2=`sed $PATTERN $TEMPLATE2` echo $MAP_DEF1 >> $TMP echo $MAP_DEF2 >> $TMP fi done)